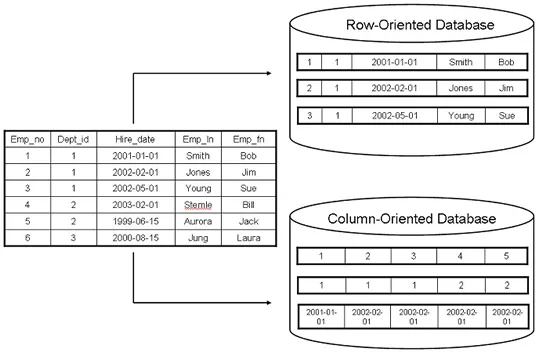
- 가장 쉽게 접근하는 방법은 원본과 똑같은 공간을 하나 더 만들어서 순차적으로 탐색하는 방법이다. 이 경우 공간복잡도가 O(mn)이며 문제에서는 권장하지 않는 방법이다.
- 그 다음의 접근하는 방법은 0이 있는 위치를 기억하는 것이다. row 와 column 을 각각 체크할 수 있는 공간을 만든다면 공간복잡도는 O(m) + O(n)이 된다. 간단히 살펴보면 다음과 같다.
Row, Column에 대해서 0인 위치를 기억
// o(m+n)
public void setZeroes(int[][] matrix) {
int n = matrix.length;
int m = matrix[0].length;
int[] rowCheck = new int[n];
int[] columnCheck = new int[m];
for(int i=0; i<n; i++){
for(int j=0; j< m ; j++){
if(matrix[i][j] == 0) {rowCheck[i]=1; columnCheck[j]=1;}
}
}
for(int i=0; i<n; i++){
if(rowCheck[i]==1){
for(int j=0;j<m;j++){
matrix[i][j]=0;
}
}
}
for(int j=0; j<m ; j++){
if(columnCheck[j]==1){
for( int i=0; i<n; i++){
matrix[i][j]=0;
}
}
}
}
- 최초 입력받은 matrix에서 row와 column에 '0' 인 위치를 기억해두었다가 해당 위치의 값을 변경하는 방식이다.
- 그렇다면 문제에서 제안하는 Best Solution은 무엇일까? 제공되는 힌트를 보면
# Hint 1 (추가 메모리 공간이 없도록 manipulate)
If any cell of the matrix has a zero we can record its row and column number using additional memory. But if you don't want to use extra memory then you can manipulate the array instead. i.e. simulating exactly what the question says.
# Hint 2 (불일치가 일어나지 않도록 market관리)
Setting cell values to zero on the fly while iterating might lead to discrepancies. What if you use some other integer value as your marker? There is still a better approach for this problem with 0(1) space.
# Hint 3 (row/columns를 분리해서 생각하기 보다는 하나로 가져갈수 있는방법)
We could have used 2 sets to keep a record of rows/columns which need to be set to zero. But for an O(1) space solution, you can use one of the rows and and one of the columns to keep track of this information.
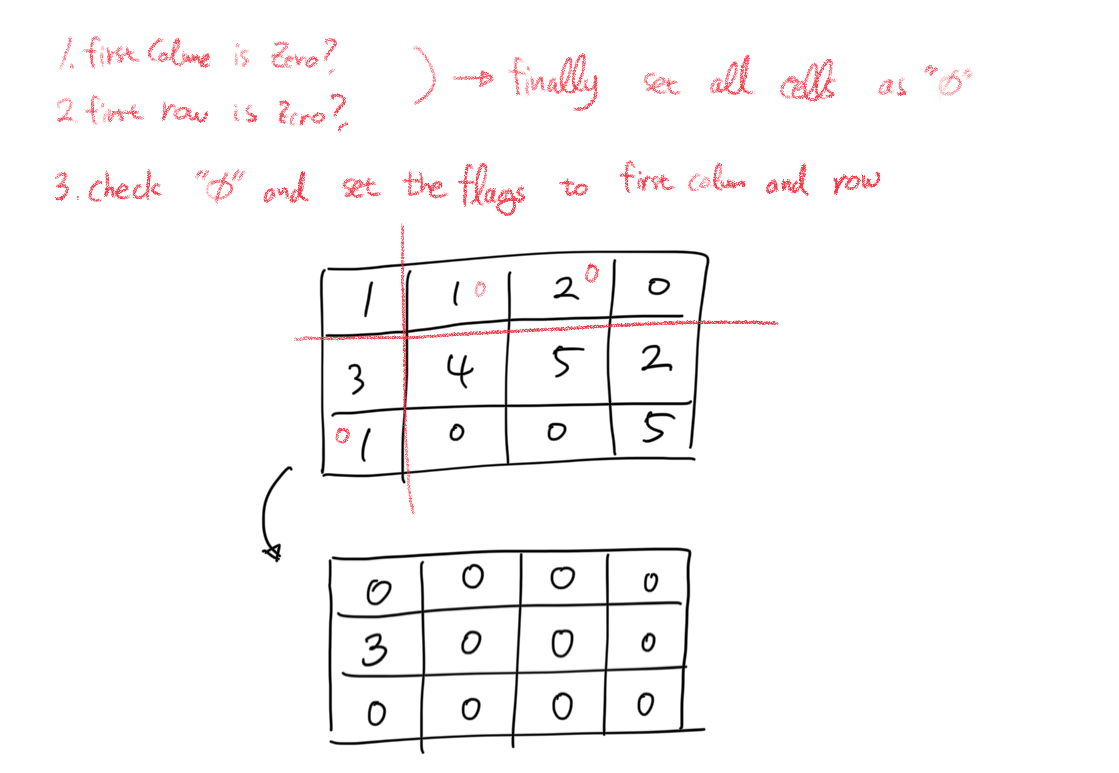
# Hint 4 (! 모든 행과열의 첫번째 셀을 flag로 사용할 수 있다.)
We can use the first cell of every row and column as a flag. This flag would determine whether a row or column has been set to zero.
이와 같은 힌트를 동해 다음과 같이 접근해보자.
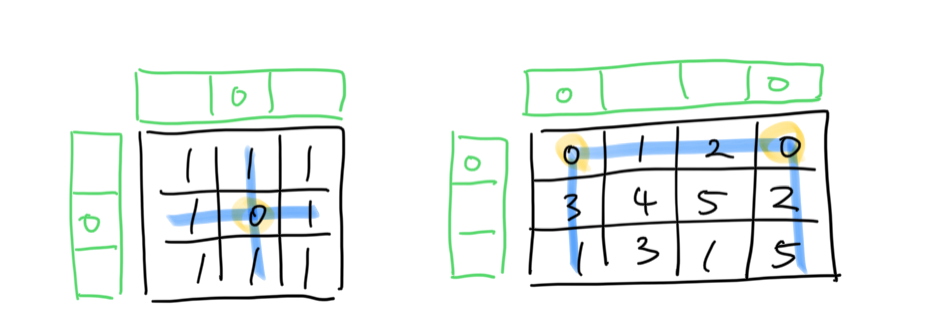
첫번째 행과 첫번째 열을 flag marker로 사용한다.
1. 첫번째 행과 첫번째 열을 우리가 위에서 마련했던 O(m+n) 의 공간으로 사용한다.
2. 단 이 때 기존에 세팅되어 있던 값을 보존해야 한다. 이후 matrix의 값을 "0"을 치환하는 과정에서 첫번째 행과 열의 값을 참조해야 하는데 값이 구분되지 않아서 불일치가 일어날 수 있다.
3. 따라서 최초 첫번째 행과 열에 있던 값을 기억하여 나중에 일괄처리 할 수 있도록 하며, 2번의 변환과정의 범위에서 첫번째 행과 열은 제외해야 한다.
- 나열되어 있는 문자열을 하나씩 꺼내어 만들면서 인접한지 체크하는 방법은 시간복잡도를 초과하게 됩니다.
<접근법>
- s : [1~500]
- 영어 소문자 26개가 나타날 수 있습니다.
- 같은 문자가 인접하지 않으려면 각 문자를 돌아가면서 선택하여 결과 문자열을 만드는 것으로 생각할 수 있습니다.
e.g) aabb -> abab, aaabbc -> acabab / ababac
- 그렇다면 가장 자주 나타나는 문자를 먼저 사용하는 것이 유리하겠습니다.
- 같은 빈도수라면 우선순위를 정해야 겠습니다. (영어일 경우 알파벳순이 일반적입니다.)
<Key point>
- 가장 자주 나타나는 문자를 알기 위해서는 먼저 각 문자의 count를 구해야 합니다.
시간복잡도 O(s) : s가 500이므로 충분합니다.
- 자주 나타나는 문자를 먼저 사용하기 위해서는 MaxHeap의 자료구조가 필요합니다.
시간복잡도 O(log(x)) : 문자의 종류는 26가지 입니다. (영어소문자)
- MaxHeap에서 2개의 문자(X,Y) 를 꺼낸뒤 결과문자열을 만듭니다.
- 꺼낸 문자의 Count를 1 감소시키고 다시 넣습니다.
<boundary>
- MaxHeap에 문자가 1개만 남은경우는 ?? (현재 남은 문자 Z)
a) 해당 문자의 count가 1이상이라면 : 이후 만들어지는 문자열은 같은 문자가 인접할 수 밖에 없습니다. -> 불가능
b) 해당 문자의 count가 1이라면 : 이전 결과 문자열을 만들때 MaxHeap에서 꺼낸 문자가 X,Y 라고 하고 Y!=Z 이면 가능
1. Y=Z 가 되는 케이스
Y=Z 이라면 꺼낼당시 Y:2 이며 -> X:1 , Y:2 인 경우는 MaxHeap의 정의에 모순이 됨
또한 X:2이상 , Y:2 인 경우는 MaxHeap 문자가 1개 남는다는 가정과 모순이 됨
2. 따라서 Y!=Z 인 경우만 가능함
Y!=Z 이라면 꺼낼당시 Y:1 이며 -> Z(1) 관계없이 성립
<solution>
import java.util.Comparator;
import java.util.PriorityQueue;
public class ReorganizeString {
public class Info{
public char key;
public int count;
public Info(char key, int count){
this.key=key;
this.count=count;
}
}
public static void main(String[] args){
ReorganizeString module = new ReorganizeString();
module.reorganizeString("aab");
}
public String reorganizeString(String S) {
String ret = "";
int[] array = new int[26];
for(int i = 0; i < S.length(); i++){
array[S.charAt(i) - 'a']++;
}
PriorityQueue<Info> pq = new PriorityQueue<Info>(new Comparator<Info>() {
@Override
public int compare(Info o1, Info o2) {
return (o1.count - o2.count)* - 1;
}
});
for(int i = 0; i < 26; i++){
if(array[i] > 0 ) {
pq.add( new Info((char)(i+'a'), array[i]) );
}
}
while(!pq.isEmpty()){
if(pq.size() > 1){
Info a = pq.poll();
Info b = pq.poll();
ret += a.key;
ret += b.key;
a.count--;
b.count--;
if(a.count > 0 ){
pq.add(a);
}
if(b.count > 0 ){
pq.add(b);
}
}else{
Info a = pq.poll();
if(a.count ==1){
ret +=a.key;
}else{
ret="";
}
}
}
return ret;
}
}
- 과거 Hadoop Eco에서도 Hive, Impala, Presto와 같은 다양한 소프트웨어가 있었는데, 수년간 시스템을 구축해본 결과 같은 생태계 내에서 동등한 발전속도를 가지고 있다는 전제라면 자신의 케이스와 매칭이 잘 되는 솔루션을 선택하는 것이 매우 중요합니다.
- 반대로 이야기하면 생태계의 규모가 크고, 발전속도가 빠른 (자주 릴리즈 되는) 소프트웨어는 다 이유가 있다로 설명할 수 있습니다. (다양한 케이스를 흡수하면서, 기존 케이스의 확장성을 보완하는 경우들입니다.)
- 두 제품의 성능 비교는 생략하고 Redshift내에서 선택하는 Node 타입에 대해서만 비교를 해보았습니다. (실무에서 그렇게 까지 사용해 볼만한 비용이나 시간여유가 없었습니다. 다음에 GCP를 사용하게 될 기회가 생기면 비교해보겠습니다.)
<고밀도 컴퓨팅 DC2 vs 고밀도 스토리지 DS2>
고밀도 컴퓨팅 DC2
vCPU
메모리
스토리지 용량
I/O
요금
dc2.large
2
15 GiB
0.16TB SSD
0.60 GB/s
0.30 USDper Hour
dc2.8xlarge
32
244 GiB
2.56TB SSD
7.50 GB/s
5.80 USDper Hour
고밀도 스토리지 DS2
vCPU
메모리
스토리지 용량
I/O
요금
ds2.xlarge
4
31 GiB
2TB HDD
0.40 GB/s
1.15 USDper Hour
ds2.8xlarge
36
244 GiB
16TB HDD
3.30 GB/s
9.05 USDper Hour
- 저장 공간이 많이 필요하다면 DS2, 연산속도가 필요하다면 DC2를 선택하면 됩니다. (클러스터 생성 후 변경가능)
- 개발목적의 경우 large, 스테이징 / 운영의 목적으로 8xlarge를 선택하였습니다.
- RedShift의 경우 노드의 수는 x2 형태로 지정가능합니다.
- large 와 8xlarge의 경우 개당 노드로 단순하게 비용을 비교하면 약 20배 정도 차이가 납니다. (large(40) vs 8xlarge(2))
<속도 및 저장공간>
- dc2.large(4) vs dc2.8xlarge(2) 의 성능을 비교해 보았습니다. 소요된 Cost는 약 10배정도 입니다.
- dc2.large(4)의 경우 640GB 저장공간이 제공되며, dc2.8xlarge(2) 의 경우 5.1TB가 제공됩니다.
- 쿼리별 수행 속도 (캐시, 네트워크/CPU 상황등 고려해야하는 변수들이 있기 때문에 단순참고로만 보시길 바랍니다.)
쿼리 유형
dc2.large(4)
dc2.8xlarge(2)
#1
1.2초
0.01초
#2
6.5초
0.5초
#3
7.1초
1초
#4
7.2초
0.9초
#5
8.5초
1.2초
#6
1분30초
10초
#7
3분
16초
- 대략 300개의 쿼리를 수행하는데 dc2.large(4) 에서 19분정도 소요되던 작업이 dc2.8xlarge(2)내에서 약1분30초 정도에 완료되는것을 확인할 수 있었습니다.
- 정리해보면 제공되는 저장공간은 약 8배, 처리속도는 약 9.5배정도에 근접합니다.
(들어간 비용대비 정직한 결과를 보여줍니다.)
<정리>
AWS Redshift
- 클러스터 생성 후 노드타입을 변경하는 것도 가능합니다. 단, 적재되어 있는 데이터량에 따라서 다운타임이 존재
- Scale out 을 통해서 얻어지는 성능향상 효과도 있으나, 대규모 분산/병렬처리가 필요한 쿼리에만 해당하며
일반적인 쿼리에서는 Scale up을 통한 vCPU, 메모리, I/O 의 성능향상 효과가 눈에 보입니다.
일반적인 선택가이드
- 대량의 비정형/반정형 데이터의 단순 가공의경우 S3로 Pipeline을 구축하고 Athena 로 검색하는 것이 가장 효율적
- Join이 없으며 수천만건 이상의 대량의 데이터를 쉽게 Scale out할 수 있는 구조를 원한다면 NoSQL
- Join이 필요하며 대규모 분석쿼리 및 표준SQL, 다양한 인터페이스가 필요한 경우 OLAP
- 트랜잭션처리가 가장 중요한 경우면 OLTP
<각 Public Cloud에 대한 개인적인 의견 + 동향>
- AWS의 경우 IaaS로 출발했던 구조로 인하여 상대적으로 Azure, GCP 에 비해서 Full manage, serverlees 솔루션이 부족
- GCP의 경우 BigTable, BigQuery가 뛰어난 성능을 가지고 있기 때문에, 최근 데이터처리에 특화된 어플리케이션이 필요한 경우 선택하는 수요가 늘고 있음
spring:
profiles: dev
datasource:
driver-class-name: com.amazon.redshift.jdbc42.Driver
url: jdbc:redshift://localhost:5439/dev
username:
password:
- docker file을 작성한다.[Dockerfile]
FROM openjdk:8-jdk-alpine
ARG JAR_FILE=target/*.jar
COPY ${JAR_FILE} app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
- maven package를 수행하고 다음과 같이 Docker 이미지를 build한다.
docker build -t {service-name} .
- docker 를 실행한다.
docker run -p 8200:8200 {service-name}
<오류상황>
- Local에서는 잘 동작하던 Application이 Docker 이미지에서는 잘 되지 않는 현상이 발생한다.
- 오류로그를 보면 다음과 같다.
Caused by: org.hibernate.HibernateException: Access to DialectResolutionInfo cannot be null when 'hibernate.dialect' not set
at org.hibernate.engine.jdbc.dialect.internal.DialectFactoryImpl.determineDialect(DialectFactoryImpl.java:100) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
at org.hibernate.engine.jdbc.dialect.internal.DialectFactoryImpl.buildDialect(DialectFactoryImpl.java:54) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
at org.hibernate.engine.jdbc.env.internal.JdbcEnvironmentInitiator.initiateService(JdbcEnvironmentInitiator.java:137) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
at org.hibernate.engine.jdbc.env.internal.JdbcEnvironmentInitiator.initiateService(JdbcEnvironmentInitiator.java:35) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
at org.hibernate.boot.registry.internal.StandardServiceRegistryImpl.initiateService(StandardServiceRegistryImpl.java:94) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
at org.hibernate.service.internal.AbstractServiceRegistryImpl.createService(AbstractServiceRegistryImpl.java:263) ~[hibernate-core-5.3.7.Final.jar!/:5.3.7.Final]
... 41 common frames omitted
hibernate dialect 가 설정되지 않았다는 내용이다.
일반적으로는 명시하지 않아도 추천되어서 hibernate가 자동으로 지정하는데 docker내에서는 오류가 발생하는 것을 확인할 수 있다.
(자세한 원인파악이 필요하다. 우선은 해당 dialect를 명시하여 오류를 수정한다.)
- AWS Redshift는 PostgreSQL 8.0.2. 을 기반으로 수행되기 때문에 다음과 같이 Spring JPA를 세팅한다.
공통적인 로직을 Service Layer 에 두면 다른 REST API 나 Controller 활용할 때에도 별도로 검증로직을 추가하지 않아도 됩니다.
또한 값의 의미를 검증하는 부분은 비지니스와 연관성이 있다고 판단하였습니다.
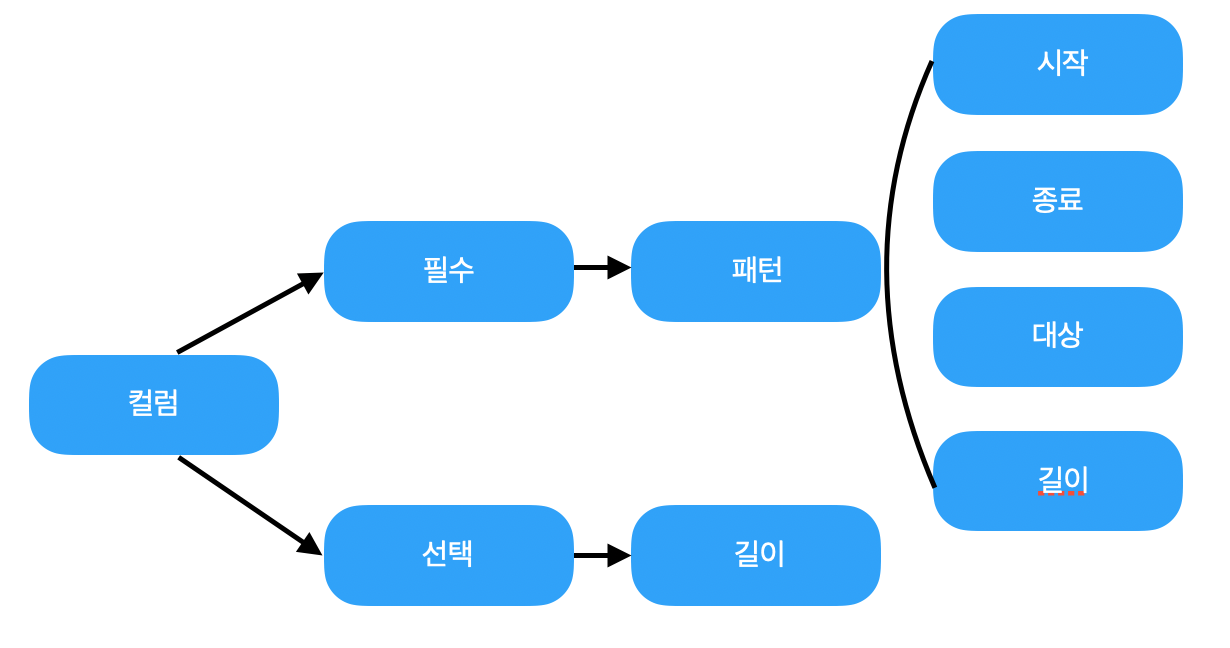
먼저 서비스명과 서비스코드의 문자패턴을 정규표현식으로 나타냅니다.
문자패턴을 정규표현식으로 나타내면서 (시작문자,종료문자,트림,길이 등) 에 대한 처리를 합니다.
public class ValidationPattern {
public final static Pattern serviceNamePattern = Pattern.compile("(^[a-z][a-z0-9]{1,19}$)");
public final static Pattern serviceCodePattern = Pattern.compile("(^[a-z][a-z0-9-]{1,19}$)");
}
이후 해당 패턴을 이용하여 검증하는 로직을 구현합니다.
@Service
public class ServiceService {
@Autowired
private ServiceRepository serviceRepository;
@Autowired
private ModelMapper modelMapper;
public ServiceDto createService(ServiceDto serviceDto) throws DataFormatViolationException {
String serviceCode = serviceDto.getServiceCode();
checkServiceCode(serviceCode);
ServiceEntity serviceEntity =modelMapper.map(serviceDto, ServiceEntity.class);
serviceRepository.save(serviceEntity);
return modelMapper.map(serviceEntity, ServiceDto.class);
}
private void checkServiceCode(String serviceCode) throws DataFormatViolationException {
if(serviceCode == null){
throw new DataFormatViolationException("Code value should be not null");
}else{
Pattern codePattern = ValidationPattern.serviceCodePattern;
Matcher matcher = codePattern.matcher(serviceCode);
if(!matcher.matches()){
throw new DataFormatViolationException("Code value should be consist of alphabet lowercase, number and '-', (length is from 2 to 20)");
}
}
}
7. 결론
두서없이 쓰다보니 글의 요점이 모호해진 것 같습니다.
정리해보면...
- 어떠한 문제를 해결하기 위해서 바로 코딩으로 뛰어들어서는 안된다.
- 문제를 재해석하여 나만의 방식으로 표현하고 시간복잡도 / 공간복잡도 를 정리한다.
- 로직은 최대한 간결하게! 대/중/소, 중복없이, 누락없이!
- MVC 의 경우 각 Layer의 하는 일들이 나누어져 있다.
- 만약 시간복잡도가 높은 연산이 있다면 이러한 연산은 최소한으로 해주는 것이 좋고, 이러한 필터링을 각 Layer별로 해주면 효과적이다.