<개요>
Spring @EventListener 를 활용한 Refactoring
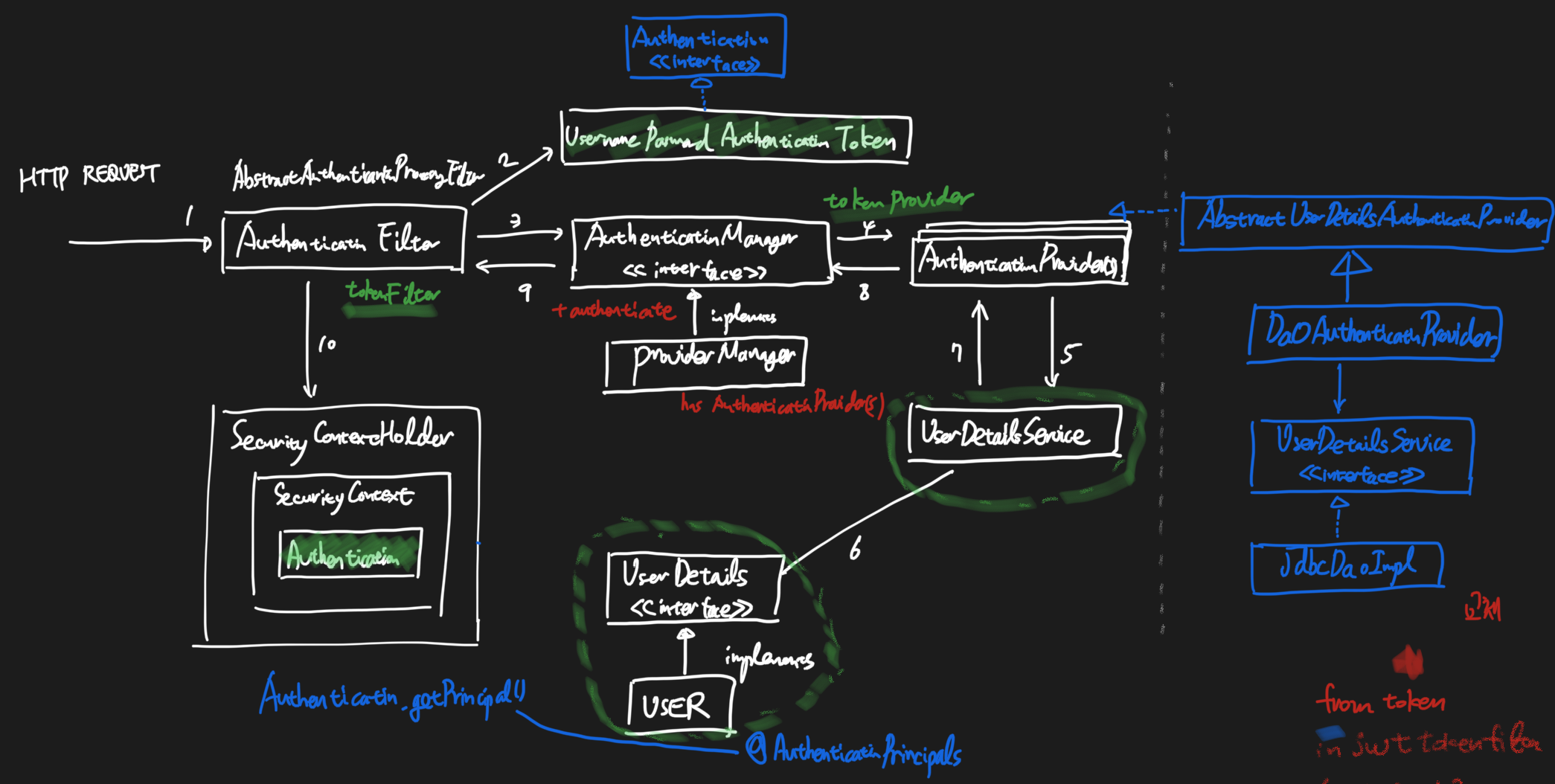
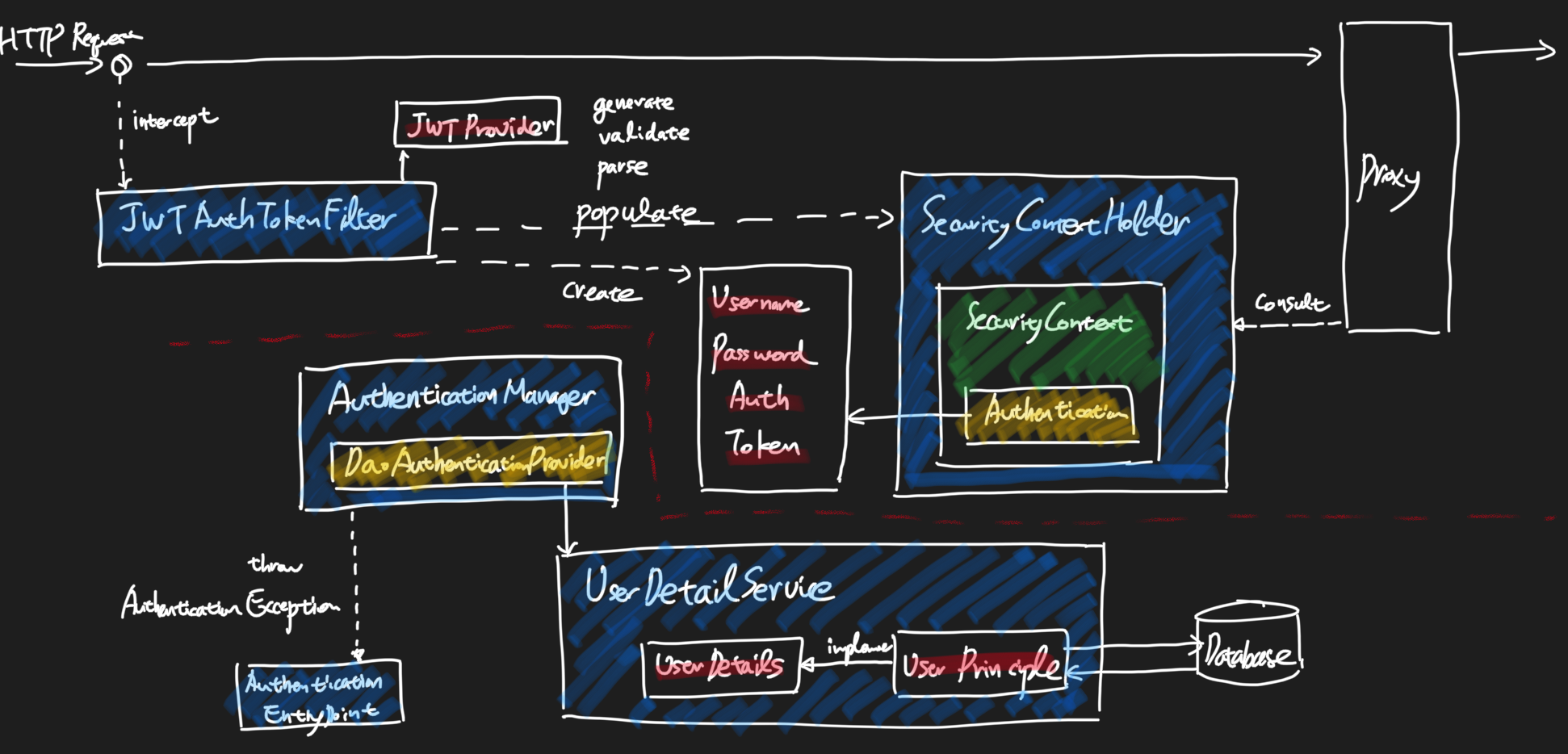
<개요> - 서비스 내에서 로직 처리후 타 서비스 연동을 위해서 Service Call을 다시 하는 구조 - Spring에서 제공하는 ApplicationEvent, ApplicationListener를 활용하여 리팩토링 <내용> - 현재 서비스내에서 다..
icthuman.tistory.com
- 이후 Slack API를 호출하는 중 오류가 간헐적으로 발생함
<내용>
2022-02-15 13:01:43.176 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : Enabled protocols: [TLSv1.3, TLSv1.2, TLSv1.1, TLSv1]
2022-02-15 13:01:43.176 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : Enabled cipher suites:[TLS_AES_128_GCM_SHA256, TLS_AES_256_GCM_SHA384, TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384, TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256, TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384, TLS_RSA_WITH_AES_256_GCM_SHA384, TLS_ECDH_ECDSA_WITH_AES_256_GCM_SHA384, TLS_ECDH_RSA_WITH_AES_256_GCM_SHA384, TLS_DHE_RSA_WITH_AES_256_GCM_SHA384, TLS_DHE_DSS_WITH_AES_256_GCM_SHA384, TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256, TLS_RSA_WITH_AES_128_GCM_SHA256, TLS_ECDH_ECDSA_WITH_AES_128_GCM_SHA256, TLS_ECDH_RSA_WITH_AES_128_GCM_SHA256, TLS_DHE_RSA_WITH_AES_128_GCM_SHA256, TLS_DHE_DSS_WITH_AES_128_GCM_SHA256, TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA384, TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384, TLS_RSA_WITH_AES_256_CBC_SHA256, TLS_ECDH_ECDSA_WITH_AES_256_CBC_SHA384, TLS_ECDH_RSA_WITH_AES_256_CBC_SHA384, TLS_DHE_RSA_WITH_AES_256_CBC_SHA256, TLS_DHE_DSS_WITH_AES_256_CBC_SHA256, TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA, TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA, TLS_RSA_WITH_AES_256_CBC_SHA, TLS_ECDH_ECDSA_WITH_AES_256_CBC_SHA, TLS_ECDH_RSA_WITH_AES_256_CBC_SHA, TLS_DHE_RSA_WITH_AES_256_CBC_SHA, TLS_DHE_DSS_WITH_AES_256_CBC_SHA, TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA256, TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA256, TLS_RSA_WITH_AES_128_CBC_SHA256, TLS_ECDH_ECDSA_WITH_AES_128_CBC_SHA256, TLS_ECDH_RSA_WITH_AES_128_CBC_SHA256, TLS_DHE_RSA_WITH_AES_128_CBC_SHA256, TLS_DHE_DSS_WITH_AES_128_CBC_SHA256, TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA, TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, TLS_ECDH_ECDSA_WITH_AES_128_CBC_SHA, TLS_ECDH_RSA_WITH_AES_128_CBC_SHA, TLS_DHE_RSA_WITH_AES_128_CBC_SHA, TLS_DHE_DSS_WITH_AES_128_CBC_SHA]
2022-02-15 13:01:43.176 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : Starting handshake
2022-02-15 13:01:43.221 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : Secure session established
2022-02-15 13:01:43.221 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : negotiated protocol: TLSv1.3
2022-02-15 13:01:43.221 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.c.ssl.SSLConnectionSocketFactory : negotiated cipher suite: TLS_AES_128_GCM_SHA256
2022-02-15 13:01:43.223 DEBUG 9926 --- [nio-8800-exec-3] o.a.h.conn.ssl.DefaultHostnameVerifier : peer not authenticated
javax.net.ssl.SSLPeerUnverifiedException: peer not authenticated
at java.base/sun.security.ssl.SSLSessionImpl.getPeerCertificates(SSLSessionImpl.java:526) ~[na:na]
at org.apache.http.conn.ssl.DefaultHostnameVerifier.verify(DefaultHostnameVerifier.java:97) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.verifyHostname(SSLConnectionSocketFactory.java:503) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.createLayeredSocket(SSLConnectionSocketFactory.java:437) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:384) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:142) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:376) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:393) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:236) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) ~[httpclient-4.5.13.jar:4.5.13]
at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:56) ~[httpclient-4.5.13.jar:4.5.13]
at org.springframework.http.client.HttpComponentsClientHttpRequest.executeInternal(HttpComponentsClientHttpRequest.java:87) ~[spring-web-5.3.7.jar:5.3.7]
at org.springframework.http.client.AbstractBufferingClientHttpRequest.executeInternal(AbstractBufferingClientHttpRequest.java:48) ~[spring-web-5.3.7.jar:5.3.7]
at org.springframework.http.client.AbstractClientHttpRequest.execute(AbstractClientHttpRequest.java:66) ~[spring-web-5.3.7.jar:5.3.7]
at org.springframework.http.client.InterceptingClientHttpRequest$InterceptingRequestExecution.execute(InterceptingClientHttpRequest.java:109) ~[spring-web-5.3.7.jar:5.3.7]- 동기방식으로 순차처리할 경우 문제가 없으나 비동기식으로 대량 동시호출시 해당 오류가 간헐적으로 발생하고 있음
<정리>
- 관련이슈를 살펴보면 다음과 같다.
TLSv1.3 handshake is failing, but passes on TLSv1.2 on JDK 11. It also doesn't fail in TLSv1.2 on JDK 10
TLS 1.3 사용시 SSLSessionImpl 생성할때 PostHandshakeContext로 부터 값을 가져와서 생성하게 됨 (not ClientHandshakeContext)
PostHandshakeContext은 requestedServerNames 에 값을 할당하지 않고 있어서 빈값으로 문제가 발생함
TransportContext의 conSession필드에서 서버목록을 가져오도록 하여 해결할 수 있음
<참조>
https://github.com/slackapi/java-slack-sdk/issues/482
https://github.com/slackapi/java-slack-sdk/issues/465#issuecomment-632150000
https://github.com/slackapi/java-slack-sdk/pull/452
Add a workaround for OpenJDK 11's bug by seratch · Pull Request #452 · slackapi/java-slack-sdk
Summary Sending HTTP requests to Slack API server on OpenJDK 11 fails due to https://bugs.openjdk.java.net/browse/JDK-8211806 Requirements (place an x in each [ ]) I've read and understood th...
github.com
'Java' 카테고리의 다른 글
| ObjectMapper 사용시 주의점 (0) | 2022.05.18 |
|---|---|
| OpendJDK 9 사용중 Troubleshooting (0) | 2022.02.17 |
| Spring @EventListener 를 활용한 Refactoring (0) | 2022.02.15 |
| Spring JPA + H2 사용시 GenerationType.IDENTITY 오류 (0) | 2022.01.17 |
| Spring Security 기능 활용 #2 (Configuration, WebSecurityConfigurerAdapter) (1) | 2022.01.10 |