<가상의 시나리오>
- Ingestion Layer에서 수백개의 병렬처리를 통해서 데이터를 생성하고 있으며, 해당 데이터에 접근할 수 있도록 파티션별로 Raw API 제공되고 있음
- Role, Scheduler, Auth 등등 여러 가지 문제 때문에 신규 API 를 만드는 데 시간이 필요함 (파티션별로 나누어진 데이터를 합쳐서 연산해야 함)
- Application Layer에서 Raw API들을 반복 호출하여 결과값을 연산하도록 로직을 구성하도록 하며 최대한 처리속도를 끌어올리고 자원효율을 극대화하자.
<접근방법>
- 다수의 API 호출 후 결과를 조합해야 하는 경우 Web client를 활용하여 비동기 호출로 효과를 봤었다. (이전 포스트 참조)
Spring WebClient 사용 #1
- Async API Call 후 응답을 제대로 처리하지 못하는 현상이 있습니다. - 그 여파로 내부적으로 AtomicInteger를 이용하여 호출Count를 처리하는 로직이 있는데 해당 로직이 수행되지 않아서 버그가 발생
icthuman.tistory.com
Spring WebClient 사용 #2 (MVC + WebClient 구조)
- Spring 이후 버전에서는 RestTemplate가 deprecated될 예정이며 WebClient 사용을 권장하고 있다. - 현재 구성 중인 시스템에는 동기/비동기 API가 혼재되어 있으면서, 다양한 Application / DB를 사용중이기 때
icthuman.tistory.com
https://icthuman.tistory.com/entry/Spring-WebClient-%EC%82%AC%EC%9A%A9-3-Configuration-Timeout
Spring WebClient 사용 #3 (Configuration, Timeout)
이전글 Spring WebClient 사용 #2 (MVC + WebClient 구조) Spring WebClient 사용 #2 (MVC + WebClient 구조) - Spring 이후 버전에서는 RestTemplate가 deprecated될 예정이며 WebClient 사용을 권장하고 있다. - 현재 구성 중인 시
icthuman.tistory.com
- 신규 프로젝트에서는 기술스택을 Spring WebFlux 로 선정하였다. 그 이유는 다음과 같다.
a. 기본적으로 Spring, Java에 대한 이해도가 높다. 하지만 Legacy 코드는 없다.
b. 데이터에 대한 읽기 연산이 대부분이고, 특별한 보안처리나 트랜잭션 처리가 필요없다. (참조해야할만한 Dependecny 가 적다.)
c. 저장공간으로 Redis Cache를 활용한다. 즉, Reactive를 적극 활용할 수 있다.
d. 다수의 API 호출을 통해서 새로운 결과를 만들어 낸다.
즉, IO / Network의 병목구간을 최소화 한다면 자원활용을 극대화 할 수 있을 것으로 보인다.
<진행내용>
- 기존의 For loop 방식과 Async-non blocking 차이,그리고 Mono / Flux 를 살펴본다. (Spring WebFlux)
@ReactiveRedisCacheable
public Mono<String> rawApiCall(...) throws .Exception {
Mono<String> response = webClient
.get()
.uri(url)
.retrieve()
.onStatus(HttpStatus::is4xxClientError, clientResponse -> Mono.error(new Exception(...)))
.onStatus(HttpStatus::is5xxServerError, clientResponse -> Mono.error(new Exception(... )))
.bodyToMono(String.class)
.timeout(Duration.ofMillis(apiTimeout))
.onErrorMap(ReadTimeoutException.class, e -> new Exception(...))
.onErrorMap(WriteTimeoutException.class, e -> new Exception(...))
.onErrorMap(TimeoutException.class, e -> new Exception(...));
return response;
}webClient를 이용해서 타 API를 호출하는 부분이다. 응답값에는 다수의 건이 포함되어 있으나 해당 데이터를 보내는 쪽에서도 병렬처리를 진행하고 있기 때문에 Collection 이나 Array 형태로 처리하는 부분을 제외하고 그냥 Raw line 형태로 제공하고 있다.
Spring MVC기반에서는 이 값을 꺼내기 위해서 결국 block하고 값에 접근하는 로직이 필요하다. 굳이 코드로 구현하자면 아마도 이렇게 만들어 질 것이다.
List<ApiResponse> ret = new ArrayList<>();
for(String value : Collection ... ){
String contents = apiService.rawApiCall(value).block();
String[] lines = contents.split("\n");
for(String data : lines){
if(StringUtils.hasText(data)){
ApiResponse apiResponse = mapper.readValue(data, ApiResponse.class);
if(populationHourApiResponse .. ){
// biz logic
FinalResponse finalResponse = new FinalResponse();
// setter
...
..
ret.add(finalReponse);
}
}
}
}이 코드에는 여러가지 문제점이 있는데
- block()을 수행하게 되면 비동기 넌블러킹 처리의 여러 장점이 사라진다.
- 오히려 더 적은 수의 쓰레드를 사용해야 하는 구조특성상 block이 생기면 더 병목이 발생하는 경우도 있다.
- return 에 얼만큼의 데이터가 담길지 모르게 된다.
- API Call 이후 biz logic의 수행시간이 길어질 수록 전체 응답시간은 더욱 길어진다.
해당 내용을 block없이 처리하도록 Flux를 최대한 활용하여 작성해보았다.
public Flux<FinalResponse> getDataByConditionLevel1{
List<Mono<String>> monoList = new ArrayList();
for(String value : Collections ...)){
monoList.add( apiService.rawApiCall(value) );
}
return
Flux.merge(monoList)
.flatMap(s -> Flux.fromIterable(Arrays.asList(s.split("\n"))))
.filter(s -> StringUtils.hasText(s))
.map(data -> {
try {
return mapper.readValue(data, PopulationApiResponse.class);
} catch (JsonProcessingException e) {
log.error(e.getLocalizedMessage());
}
return new ApiResponse();
})
.filter(aApiResponse -> ... biz logic)
.map(apiResponse ->
new FinalResponse(...)
);
}주요하게 바뀐부분을 살펴보면 다음과 같다.
1. API응답의 결과를 block해서 기다리지 않고 Mono를 모아서 Flux 로 변환한다.
Mono는 0..1건의 데이터, Flux는 0..N건의 데이터를 처리하도록 되어있다.
즉 개별 Mono를 대기하여 처리하는 것이 아니라 하나의 Flux로 모아서 단일 Stream처럼 처리할 수 있다,.
2. 값이 아니라 행위를 넘겨준다.
Spring WebFlux에서는 기본적으로 Controller - Service - Dao 등의 Layer간 이동을 할때 Mono / Flux 를 넘겨준다.
즉, 어떠한 값을 보내는 것이 아니라 Mono / Flux로 구성된 Publisher를 전달해주면 subscribe를 통해서 실제 데이터가 발생될 때 우리가 정의한 Action을 수행하는 형태가 된다고 이해하면 될듯 하다. (Hot / Cold 방식의 차이가 있는데 일단 Skip하도록 한다.)
위의 로직은 각 개별 데이터 간의 연산이나 관계가 없기 때문에 비교적 쉽게 변경할 수 있었다.
하지만 해당 데이터를 다시 조합하거나 Grouping 하거나 하는 경우가 있다면 약간 더 복잡해질 수 있기 때문에 고민이 필요하며 각 비지니스 케이스에 적합한 단위와 연산으로 재설계를 해주는 것이 좋다. ( -> 필수다 !)
예를 들어서 rawApiCall에 필요한 인자값이 yyyyMMdd hh:mm:ss 형태의 timeStamp라면 특정기간 내 시간대별 결과를 얻기 위해서는 다음과 같이 Call을 하고 조합해야 한다.
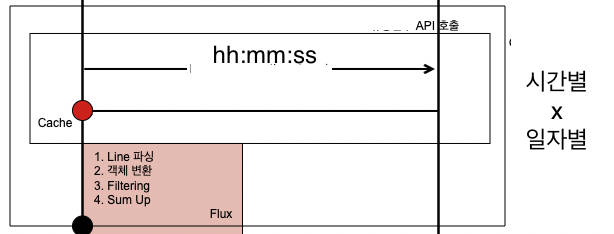
즉 수행해야 하는 액션은 다음과 같다.
- Flux를 응답받는 메소드를 다시 감싸서
- 응답결과를 적절하게 Biz Logic에 따라서 처리한 뒤
- aggreation 을 통하여 새로운 응답을 만들어 낸다. (e.g 그룹별 개수, 합계, 평균 등등)
코드로 작성해보면 이러한 형태가 될텐데
public Flux<NewResponse> getDataByConditionLevel2{
List<Flux<NewResponse>> ret = new ArrayList();
for( ; ; ){
...
// Biz Logic...
...
Flux<NewResponse> flux = getDataByConditionLevel1( ... )
.groupBy(apiSummary -> apiSummary.getKey() )
.flatMap(groupedFlux -> groupedFlux.reduce( (arg1, arg2) -> ApiSummary.add(arg1, arg2) )
.map(apiSummary -> NewResponse.valueOf( ...+ groupedFlux.key(), apiSummary ))
);
ret.add(flux);
}
return Flux.merge(ret);위의 코드에서 살펴볼 부분은 세 가지이다.
- groupBy : getDataByConditionLevel1 메소드에서 받아온 결과를 Key단위로 Grouping을 수행한다.
이때 수행결과로는 GroupedFlux가 리턴되는 데 이는 중첩된 데이터 형태로 flatMap 을 통해서 작업하는 것이 수월하다.
- reduce : groupBy 로 분류된 데이터들을 key 단위로 reduce 하게 되는데 ( 자주 보게되는 wordCount sample과 유사하다).
Java내에는 Integer , Double등의 타입에서 ::sum 메소드를 제공하고 있지만 우리가 직접 작성한 Class 에 대해서는 연산메소드를 정의해주는 것이 필요하다. 위 예제에서는 ApiSummary.add(arg1, arg2) 이다.
최종 객체변환의 편의성을 위해서 NewResponse.valueOf 메소드도 정의해서 사용하였다.
- Mono/Flux간 변환
getDataByConditionLevel1 메소드에서 살펴본것 처럼 여러 개의 Mono는 하나의 Flux로 변환이 가능하다.
또한 Flux에 대한 reduce 연산은 Mono로 변환이 된다.
그리고 여러 개의 Flux 를 합쳐서 하나의 Flux로 변환하는 것도 가능하다.
순서보장이 필요한지, 병렬처리가 필요한지 등 여러가지 요건을 고려하여 적절한 연산자를 사용하도록 한다.
<정리>
- 처음에는 blocking 로직을 벡엔드에서 가지고 있는 것이 적합하지 않아서 FrontEnd에서 해당 API들을 호출하여 결과값을 연산하는 형태로 접근했었다. (Promise all)
- 일주일치의 데이터를 기반으로 결과값을 생성하기 위해서는 총 24 * 7 = 168 회 API 호출이 필요했고, 프론트에서 처리시간은 최악의 경우 15초를 넘어가는 케이스가 발생하였다.
- Spring Web Flux를 활용하여 Backend에서 처리하도록 개선하였으며 또한 Raw API Call을 수행하는 메소드에 별도로 개발한 Cache Aspect를 적용하였다.
그 이유는 Spring Cache Manager에서 async/non-blocking에 대한 표준 구현체가 없다보니 직접 CacheMono/Flux와 ReactiveRedisTemplate등을 사용하여 값을 처리하도록 구현하였다.
이에 대한 내용은 다음 포스트에서 좀 더 자세히 다루도록 하겠다.
<결과>
- 최초 호출시 약 4~5초 정도 수행시간이 소요되며, 각 Raw API 캐시 이후에는 약 1초 정도 걸리는 것을 확인할 수 있었다.
Network 처리에 가장 많은 시간이 소요되기 때문에 사실 개별 API Call만 캐시해도 성능이 대폭 향상된다.
- 하지만 아직 몇 가지 더 살펴보고 싶은 욕심이 있는데..
a. Mono / Flux 레벨에서의 캐시
b. Raw API뿐만 아니라 최종 API에 대한 값 캐시
(각 Raw API 응답값이 변하기도 하고, 워낙 대상이 많다보니 캐시대상을 늘릴 경우 저장공간에 대한 우려가 있다.)
c. Reactor에서의 병렬처리
(Schedulers, parallel 등)
<참조>
Reactor에 대한 내용이 잘 정리되어 있다.
https://godekdls.github.io/Reactor%20Core/reactorcorefeatures/
Reactor Core Features
리액터 코어 기능 한글 번역
godekdls.github.io
Reactive Programming #1 (관련 개념정리)
최근 Reactive Programing이라는 개념이 많이 사용되고 있어서 관련하여 개념들을 정리를 해보려고 한다.1. Event DrivenReactive를 알기 위해서 먼저 Event Driven을 알아볼 필요가 있다.Event Driven은 말 그대로
icthuman.tistory.com
'Java & Spring' 카테고리의 다른 글
| Spring Boot 2.4 -> 3.2 Trouble Shooting 정리 (0) | 2024.04.18 |
|---|---|
| Spring Security 기능 활용 #3 (@AuthenticationPrincipal, UserDetails) (0) | 2024.04.03 |
| Geohash를 이용한 좌표기반 시스템 개선 (0) | 2022.07.08 |
| Spring WebClient 사용 #3 (Configuration, Timeout) (0) | 2022.05.31 |
| ObjectMapper 사용시 주의점 (0) | 2022.05.18 |
