Algorithm In Architecture #2 (Apache Kafka)
1. Message Queue
Message Queue 는 기존 레거시부터 최근까지 계속 사용되고 있는 방식입니다.
지원하는 프로토콜(MQTT, AMQP, JMS)에 따라서 분류되기도 하며 메모리 기반/디스크 기반으로 나누어지기도 합니다.
또한 Message를 처리하는 방식에 따라서 Push / Pull 방식으로 나누기도 합니다.
그리고 Queue 의 정상적인 동작을 돕기 위해서 Broker가 개입하는 것이 일반적입니다.
그러나 다양한 제품 가운데 공통적인 것이 있으니 결국은 Queue 라는 것입니다.
FIFO(First In First Out)의 메시지 처리가 필요하다는 전제로 각 시스템의 특징과 요구사항에 따라 맞춰서 솔루션을 선택하면 됩니다.
2. Message Queue 를 사용하는 이유는?
특히 Queue 는 비동기식 메시지 처리에서 많이 사용되는데 그 이유는 다음과 같습니다.
- 어플리케이션을 구현할 때 메시지가 어디서 오는지(Source), 어디로 보내야 하는지(Target) 신경쓸 필요가 없다.
- Producer는 메시지를 작성하는 데에만 집중하고 메시지 전달에 관련된 (목적지, 순서, QoS 등) 항목들에 대해서는 MQ에 모두 위임한다.
- Consumer 역시 해당 메시지를 어떻게 소모하여 처리하는 지에 대해서만 집중하면 된다.
- Producer 와 Consumer가 보다 각자의 역할에 집중할 수 있게 도와준다.
3. 자료구조 Queue
특정 자료구조에 대한 정리나 코드연습은 Algorithm 카테고리에서 자세히 소개할 예정이기 때문에 간단히 살펴봅니다.

이해를 돕기 위해서 array를 이용해서 작성한 Queue Sample입니다.
class Queue {
private static int front, rear, capacity;
private static int queue[];
Queue(int c)
{
front = rear = 0;
capacity = c;
queue = new int[capacity];
}
static void queueEnqueue(int data)
{
// check queue is full or not
if (capacity == rear) {
return;
}
// insert element at the rear
else {
queue[rear] = data;
rear++;
}
return;
}
static void queueDequeue()
{
// if queue is empty
if (front == rear) {
return;
}
else {
for (int i = 0; i < rear - 1; i++) {
queue[i] = queue[i + 1];
}
if (rear < capacity)
queue[rear] = 0;
rear--;
}
return;
}
}
-queueEnqueue
rear 는 현재 데이터를 넣어야하는 위치의 index 입니다.
만약에 capacity 만큼 꽉 차있다면 더 이상 데이터를 넣을 수 없습니다.
데이터를 넣는 것이 가능하다면 삽입 후 index를 변경합니다.
-queueDequeue
front는 데이터가 삭제되는 위치의 index입니다.
front == rear 라면 비어있는 상태입니다.
데이터를 제거하는 것이 가능하다면 제거 후 index를 변경합니다.
4. Queue 사용시 주의점
위의 sample소스를 통해서 Queue의 특징을 이해하셨다면 주의점도 파악하실 수 있습니다.
- Queue는 무한한 용량이 아니다. 적절히 소모가 이루어지지 않는다면 Queue의 모든 용량을 소모하게 되고 유실이 발생한다.
- Queue에는 많은 쓰레드들이 동시에 접근할 수 있다. enqueue/dequeue 동작은 thread-safe 해야 합니다.
Java에서는 이를 위해서 concurrent 패키지를 제공합니다.
- 서로 다른 Queue에서는 순서보장이 되지 않습니다. (당연한 말씀)
Computer Science의 기초인 DS & Algorithm은 반드시 알고 있는 것이 좋습니다.
5. Apache Kafka
많은 Message Queue 중에서 Apache Kafka는 대용량 실시간 처리에 특화된 아키텍처 설계를 통하여 우수한 TPS를 보장합니다.
기본적으로 pub-sub 구조로 동작하며, scale out과 high availability를 확보하는 것으로 유명합니다.
아키텍처상 다양한 특징이 있지만 이번 글에서는 자료구조 & 알고리즘 측면에서 살펴보겠습니다.
5-A. Multi Partition
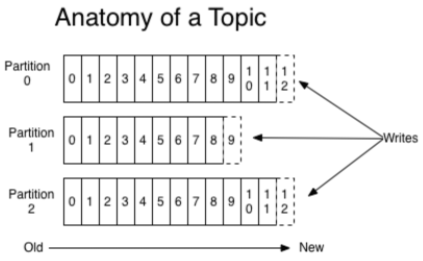
Kafka가 분산처리가 가능한 것은 Multi Partition이 가능하기 때문입니다.
대용량의 데이터가 들어올 수록 병렬처리를 통해서 속도를 확보할 수 있는 구조를 가지고 있습니다.
그렇다면 단점은 없을까요?
서로 다른 Partition에 대해서는 순서를 보장하지 않습니다.(다른 큐로 보시면 됩니다.)
예를 들어서 Partition 0 내의 메시지들끼리, Partition 1 내의 메시지들끼리 순서를 보장하지만 Partition 0과 1사이에는 순서를 보장할 수 없습니다.
반드시 순서를 보장해야 하는 케이스가 존재한다면?
- Partition 을 하나만 사용하던지
- Partitioner를 Custom 하게 작성하여 순서가 보장되어야 하는 메시지들은 같은 Partition으로 보내도록 합니다.
Topic과 혼동하시면 안됩니다. 특정 Topic내에 여러 Partition이 존재하며 Broker를 통해서 각 Topic별 Parition 의 저장정보와 복제 등이 이루어집니다.
5-B. Partitioner
Kafka의 Default Partitioner는 modulo 연산을 사용하여 파티션을 나누게 되어 있습니다.
Hash 알고리즘을 잘 작성하여 데이터를 고르게 분산하면 병렬처리 성능을 더 끌어올릴 수 있습니다.

간단한 Hash Function의 예제입니다.
private int hashFunction(K key){
int val=0;
for(int i=0; i<key.toString().length();i++){
val+= (key.toString().charAt(i)) % size;
}
return val % size;
}일반적으로 우리가 사용하는 HashMap에서도 같은 Hash값이 자주 발생할 경우 특정 row가 길어지게 되어 chaining hash table을 구현하게 되는데, 이 때 worst case로 특정 bucket에 데이터가 집중되어 메모리를 효율적으로 사용하지 못하는 경우가 발생합니다.
Kafka에서도 partition을 적절하게 분산하지 못할 경우 이러한 문제가 발생할 수 있습니다.
6. 정리
- Apach Kafka는 자료구조 Queue와 동일합니다.
- 병렬처리를 위해서 multi partiton을 지원합니다. 여러 개의 Queue 를 동시에 사용한다고 생각하면 됩니다.
- Partitioner를 어떻게 구현하는가에 따라서 partiton이 결정됩니다.
- FIFO보장이 필요한 단위에 대해서는 같은 partiton 이 적용되도록 구현합니다.
0. 참조
https://sarc.io/index.php/miscellaneous/1615-message-queue-mq
https://ko.wikipedia.org/wiki/%ED%81%90_(%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0)
https://monsieursongsong.tistory.com/
https://en.wikipedia.org/wiki/Hash_table
https://www.geeksforgeeks.org/array-implementation-of-queue-simple/