
<개요>
1. Aurora
Amazon에서 Full Managed Service로 제공하고 있는 RDB이다. MySQL, PostgreSQL과 호환되며 속도도 기존 MySQL, PostgreSQL보다 빠르도록 개선되었다.
일반적인 CRUD용도로는 크게 부족함이 없으나 현재 다루고 있는 데이터의 건수가 너무나도 많아서 분석쿼리 수행시 엄청난 시간이 소요된다. (대략 2000만건 x 수십개)
2. 트랜잭션 처리 OLTP
Aurora는 관계형 데이터베이스이며 그중에서 OLTP에 적합한 Row기반의 데이터베이스이다. 간단히 설명하자면 transaction처리를 최우선으로 하는 것이 목적이다.
<트랜잭션이란?>
작업수행의 논리적 단위를 말한다.
Database의 관점에서 시스템 트랜잭션, 사용자관점에서 비지니스 트랜잭션의 개념으로 나눌 수 있으며 일반적으로 비지니스 트랜잭션은 1개이상의 시스템 트랜잭션으로 이루어진다.
예를 들어서 계좌이체는 출금-> 입금의 단계를 거쳐야 하는데 이를 하나의 트랜잭션으로 묶어야 할 필요가 있으며 Spring과 같은 Framework에서는 Transaction Manager를 통해서 이를 Support한다.
트랜잭션의 성질 ACID를 살펴보면 그 특징을 더 자세히 알수 있다.
<Row-Oriented vs Column-Oriented>
이러한 요건을 만족시키기 위해서 일반적으로 Row-Oriented storage방식으로 접근한다. 각 Row를 기반으로 데이터를 바라보며 데이터의 정합성, 이를 위한 데이터 정규화 등을 수행한다.
Column-Oriented방식은 이와는 다르게 하나의 속성의 값들에 빠르게 접근하는 것을 목표로한다. 주로 OLAP환경에서 많이 선호한다. 대규모 분석쿼리를 수행하는 것이 주목적이다.

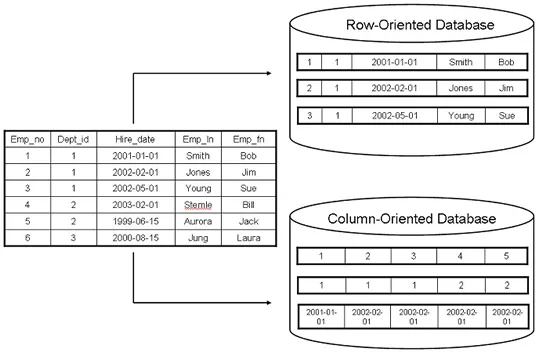
이부분에 대해서만도 책 한권의 분량이 나오기 때문에 간단히만 언급하고 지나갑니다.
3. OLAP, Big Data, 분산병렬처리



대부분의 Big Data, 그 중에서도 DataLake를 처리하는 오픈소스들은 트랜잭션을 보장하는 것이 목적이 아니라 일단 빠르게 쌓아놓고 나중에 병렬처리를 통해서 대규모 분석쿼리를 수행하여 Insight를 도출하는 것이 일반적인 목표이다.
그 특성이 OLAP과 유사하며 실제로 아키텍처도 비슷하다.
빅데이터의 출현배경과 활용방법등을 보면 과거 DatawareHouse, BI등과 99%동일하다는 것을 알수 있다.
최근에는 트랜잭션 처리에 대한 요구사항이 꾸준히 증가하여 transaction을 지원하는 기능들이 추가되고 있으나 최초 설계된 목적이 다르기 때문에 한계점이 있다. (Apache Hive)
<참고:https://icthuman.tistory.com/m/entry/Apache-hive-transaction>
Apache hive - transaction
<개요> Apache Hive는 HDFS에 저장되어 있는 파일데이터를 SQL 기반으로 처리할 수 있도록 하는 오픈소스이다. (모든 SQL을 지원하는 것은 아니며, 파일시스템 특성상 UPDATE, DELETE는 권장하지 않는다. ) 그러나..
icthuman.tistory.com
현재 BigData영역에서는 Apache Spark Eco System이 상당부분을 커버하고 있다.
(Spark Core, Streaming, SQL, MLlib) - 추후에 Aurora에서 Redshift로 마이그를 위해서 AWS에서 제공하는 Glue를 살펴볼텐데 이 역시 SparkContext를 기반으로 동작한다.
4. AWS Redshift
AWS에서 제공하는 OLAP 데이터베이스이다. 기존에 AWS에서 제공하는 Aurora, S3, RDS등의 데이터 소스와 쉽게 호환될 수 있는 것이 가장 큰 장점이다.
OLTP 대비 분석쿼리의 성능을 끌어올리기 위해서 다음과 같은 구조를 적용하였다. (일반적인 OLAP DB특성)
MPP : 대용량처리를 위해서 쿼리를 분산병렬처리 한다. 데이터를 저장할때 Distribution Key를 사용하여 적절히 분배하고 이를 기반으로 각 노드간의 데이터 이동을 최소화하여 병렬처리 성능을 극대화 한다.
Columnar data storage : Disk I/O 비용을 감소시키고 분석쿼리의 성능을 향상시킨다.
Data compression : 데이터를 압축하여 메모리에 적재후 쿼리 수행시에만 해제한다. 이를 통해서 분석쿼리 수행시 메모리를 조금더 효과적으로 사용할 수 있다.
Result caching : 수행되는 쿼리들에 대해서 캐싱한다.
5. 쿼리 수행속도 향상
기존에 약 8~10분정도 소요되던 쿼리가 30초 정도 걸리는 것을 확인하였다.
<참고사이트>
https://francois-encrenaz.net/what-is-a-dbms-a-rdbms-olap-and-oltp/
https://victorydntmd.tistory.com/129
https://mariadb.com/resources/blog/why-is-columnstore-important/
https://databricks.com/
https://diffzi.com/oltp-vs-olap/
https://www.dbbest.com/blog/column-oriented-database-technologies/
http://www.javachain.com/big-data-hadoop-in-data-warehouse/
'AWS Architecture' 카테고리의 다른 글
| AWS SDK for Java (CloudWatchLogsAsyncClient 사용법) (0) | 2021.07.15 |
|---|---|
| AWS S3-Athena 사용중 JDBC Driver동시성 문제 #1 (0) | 2021.04.02 |
| AWS Redshift with Spring JPA on Docker #2 (0) | 2020.09.07 |
| AWS Redshift with Spring JPA on Docker #1 (1) | 2020.07.13 |
| AWS Elastic Beanstalk 배포 트러블슈팅(Azure WebApp과 간단비교) (0) | 2020.03.12 |